Graham Higgins
- 1 Post
- 4 Comments


 2·3 years ago
2·3 years agoNo, I haven’t and I don’t intend to because I wouldn’t get anything out if the exercise. I don’t (yet?) have a deep enough model to inform comparisons with anything other than different parameter sizes of the same pre-trained models of the Meta LLAMA foundation model. What I posted was basically the results of a proof-of-method. Now that I have some confidence that the responses aren’t simply random, I guess the next step would be to run the method over the 7B/13B/30B models for i) vicuna and ii) wizard-vicuna which, AFAICT are the only pre-trained models that have been published with all three 7, 13 and 30 sizes.
It’s not possible to get the foundation model to respond to OCEAN tests but on such a large and disparate training set, a broad “neural” on everything would be expected, just from the stats. In consequence, the results I posted are likely to be artefacts arising from the pre-training - it’s plausible (to me) that the relatively-elevated Agreeableness and Conscientiousness are elevated as a result of explicit training and I can see how Neuroticism, Extroversion and Openness might not be similary affected.
In terms of the comparison between model parameter sizes, I have yet to run those tests and will report back when I have done.
I edited the post to include a link to the discord image. If there’s interest I can make a post with more details (I used Python’s
pexpectto communicate with a spawned llama.cpp process).
was thinking of doing a daily quantized models post just for keeping up with the bloke
Wouldn’t go amiss.
The best way to grow a community is to share the highest quality information possible. The reason I actually stopped being a lurker is because another Lemmy user told me this.
Okay, point taken. I’ve been guilty of lurking inappropriately and I can model the consequences of that.
I have a reasonable amount of direct experience of purposeful llama.cpp use with 7B/13B/30B models to offer. And there’s a context - I’m exploring its potential role in the generation of content, supporting a sci-fi web comic project - hardly groundbreaking, I know but I’m hoping it’ll help me create something outside the box.
For additional context, I’m a cognitive psychologist by discipline and a cognitive scientist by profession (now retired) and worked in classic AI back in the day.
Over on TheBloke’s discord server, I’ve been exposing the results of a small variety of pre-trained LLM models’ responses to the 50 questions of the OCEAN personality questionnaire, presented 25 times to each - just curious to see whether there was any kind of a reliable pattern emerging from the pre-training:
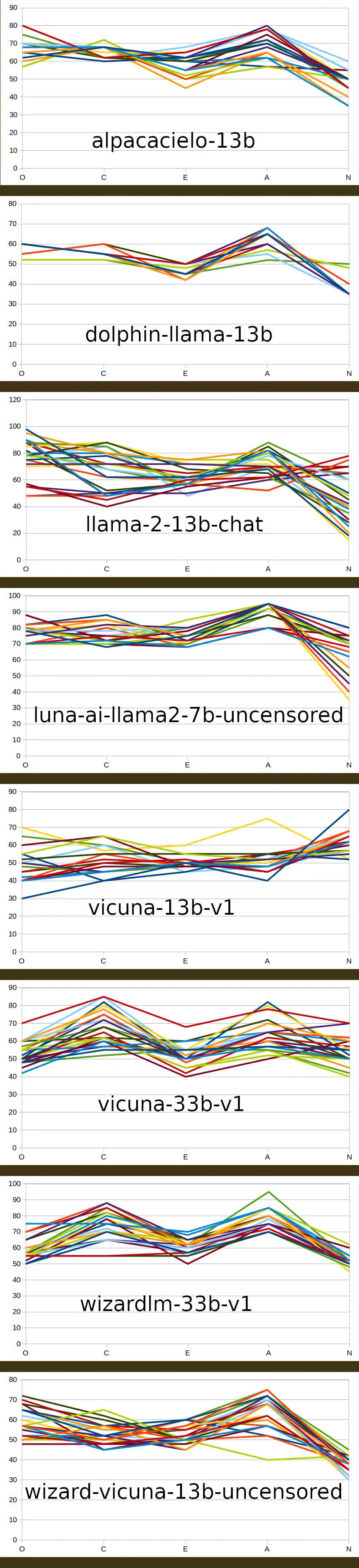
OCEAN questionnaire full-size jpeg
Looks like the larger models enable a wider range of responses, I guess that’s an expected consequence of a smoother manifold.
Happy to answer any questions that people may have and will be posting more in future.
Cheers, Graham
{kind=link}
Informative, even to relatively ignorant me.