

8·
3 hours ago… I really hoped that this wasn’t a thing, but im not surprised in the least.
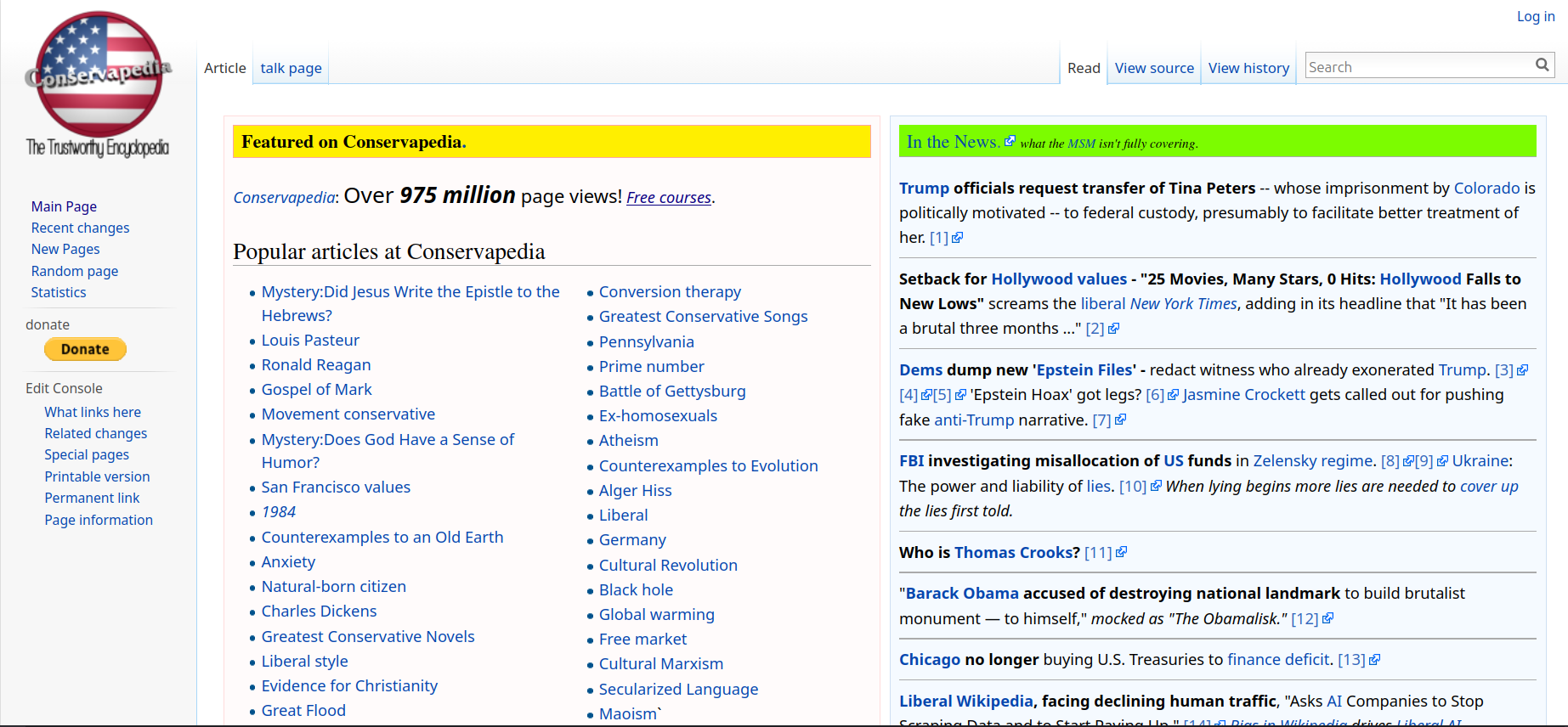
Its just fucking painful, man.
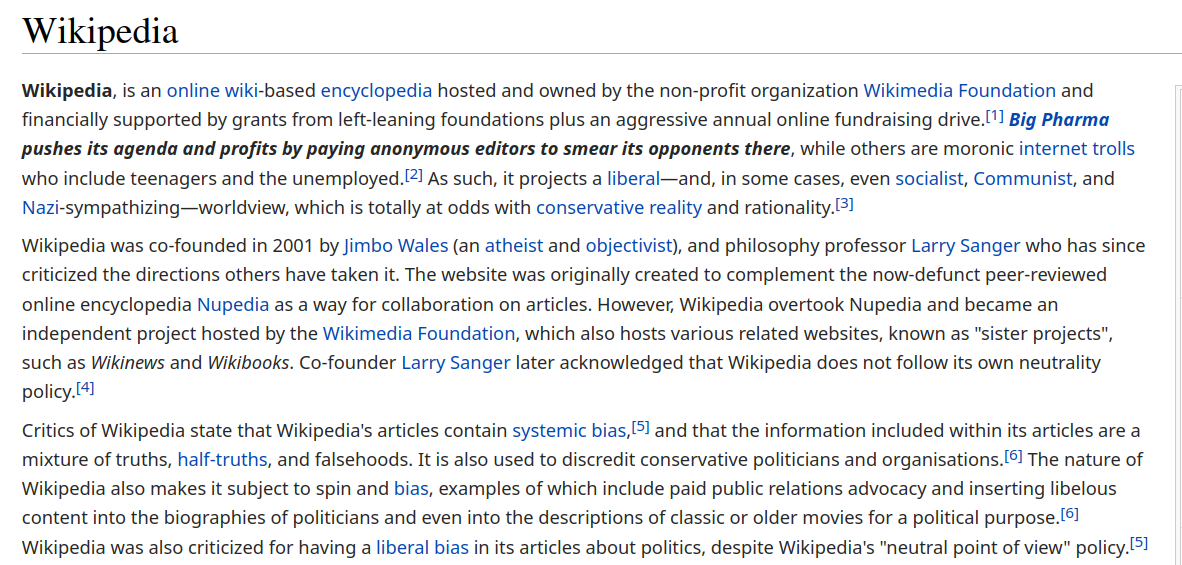

… I really hoped that this wasn’t a thing, but im not surprised in the least.
Its just fucking painful, man.

Use a local model, learn some toolcalling and have it retrieve factual answers from a database like wolfram alpha if needed. . We have a community over at c/localllama@sh.itjust.works all about local models. if your not very techy I recommend starting with a simple llamafile which is a one click executable EXE that packages engine and model together in a single file.
Then move on to a real local model engine like kobold.cpp running a quantized model that fits in your computer especially if you have a graphics card and want to offload via CUDA or Vulcan. Feel free to reply/message me if you need further clarification/guidance
https://github.com/mozilla-ai/llamafile
https://github.com/LostRuins/koboldcpp
I would start with a 7b q4km quant see if your system can run that.
{kind=link}
Your thirst is mine, my water is yours! … Oh shit, wrong sci-fi world I think my bad