

3·
10 months agoThank you for commenting!
I did nothing and I’m all out of ideas!
Thank you for commenting!
It was a pleasure! Thank you!
I’ve never used oobabooga but if you use llama.cpp directly you can specify the number of layers that you want to run on the GPU with the -ngl flag, followed by the number.
So, as an example, a command (on linux) from the directory you have the binary, to run its server would look something like:
./llama-server -m "/path/to/model.gguf" -ngl 10
Another important flag that could interest you is -c for the context size.
This will put 10 layers of the model on the GPU, the rest will be on RAM for the CPU.
I would be surprised if you can’t just connect to the llama.cpp server or just set text-generation-webui to do the same with some setting.
At worst you can consider using ollama, which is a llama.cpp wrapper.
But probably you would want to invest the time to understand how to use llama.cpp directly and put a UI in front of it, Sillytavern is a good one for many usecases, OpenWebUI can be another but - in my experience - it tends to have more half baked features and the development jumps around a lot.
As a more general answer, no, the safetensor format doesn’t directly support quantization, as far as I know

I’ve read good things about LTX, but I’ve never used it.
AFAIK it is still a tuning of llama 3[.1], the new Base models will come with the release of 4 and the “Training Data” section of both the model cards is basically a copy paste.
Honestly I didn’t even consider the fact they would not be giving Base models anymore before reading this post and, even now, I don’t think this is the case. I went to search the announcements posts to see if there was something that could make me think about it being a possibility, but nothing came out.
It is true that they released Base models with 3.2, but there they had added a new projection layer on top of that, so the starting point was actually different. And 3.1 did supersede 3…
So I went and checked the 3.3 hardware section and compare it with the 3 one, the 3.1 one and the 3.2 one.
| 3 | 3.1 | 3.2 | 3.3 |
|---|---|---|---|
| 7.7M GPU hours | 39.3M GPU hours | 2.02M GPU hours | 39.3M GPU hours |
So yeah, I’m pretty sure the base of 3.3 is just 3.1 and they just renamed the model in the card and added the functional differences. The instruct and base versions of the models have the same numbers in the HW section, I’ll link them at the end just because.
All these words to say: I’ve no real proof, but I will be quite surprised if they will not release the Base version of 4.
Link to post on threads
zuck a day ago
Last big AI update of the year:
• Meta AI now has nearly 600M monthly actives
• Releasing Llama 3.3 70B text model that performs similarly to our 405B
• Building 2GW+ data center to train future Llama models
Next stop: Llama 4. Let’s go! 🚀
Link to post on facebook
Today we’re releasing Llama 3.3 70B which delivers similar performance to Llama 3.1 405B allowing developers to achieve greater quality and performance on text-based applications at a lower price point.
Download from Meta: –
Small note: I did delete my previous post because I had messed up the links, so I had to recheck them, whoops
deleted by creator

Nice data, but I think we should take a broader view too:
https://data.worldbank.org/indicator/NY.GDP.MKTP.CD?end=2023&locations=RU-IN&start=2019
I semi randomly picked India because it is part of BRICS and had a similar economic trajectory: It is quite interesting playing with all those nobs and labels.
In this context I think PPP - which you showed - is a good indicator of the internal quality of living, but as far as I understand it, it has an hard time showing the difference in quality and standards of the consumer products between countries, so a dip in nominal GDP is an interesting context with the PPP adjusted rise. Less expensive things, because they are less regulated?
Aside from that Russia has almost completely pivoted to a war economy which, as far as I know, tends to give a big initial boost but it stresses and makes the real (for lack of a better term) economy crash in the long run.
What do you think about this? It is an interesting topic.

I’m not sure this is going to directly affect that, because their deal talks mainly about financing for the Control game, and the other news is about movie adaptations, so probably it is going to be another team, lead by the newly re-hired Hector Sanchez, working on that…
But who knows, this kind of things are always hard to follow from the outside

Actually Obtainium is mentioned (but thank you, checking back I saw I had a typo in the github link that I had missed, and I’ve now fixed it!), but this is the first time I hear about Accrescent: is it this App store?
You are right, and I forgot to add the link to it in the opening post. I’ll edit it in!
The only text-to-audio model I can think of at the moment is Stable Audio Open, which AFAIK is rather underwhelming for your use-case, if it can even handle stuff more complex than basic sounds - and no lyrics.
It is even under the “new” membership licensing of SAI.
I remember reading about a more recent one, but I currently can’t find it, and I don’t think that that one too could handle lyrics.
I suppose the Music industry is a lot harder to fight, so not a lot of people want to entangle themself with it.
Silverbullet is like that. It is not an electron or native app, you have to run a server and then get to it from the browser.
TLDR it is best run with docker or podman, but IMHO it is pretty good.

I wish they used them all, especially XDG_CACHE_HOME which can become pretty big pretty fast.
disable this system security feature temporarily,
This should be - if I’m not mistaken - possible using the pip env var I posted about earlier, like this:
PIP_BREAK_SYSTEM_PACKAGES=1 sudo apt install howdy
Or exporting it for the current shell, before running the installation
export PIP_BREAK_SYSTEM_PACKAGES=1
But I personally highly discourage it, because - AFAIK - if it even works it will mess up the deps in your system.
I’m no python expert but reading around it seems your only real solution is using a virtual environment, through pipx or venv as you already had found out, or using the
--break-system-packages
* Allow pip to modify an EXTERNALLY-MANAGED Python installation
(environment variable: `PIP_BREAK_SYSTEM_PACKAGES`)
pip flag which, as the name suggest, should be avoided.
EDIT: After rereading I got your problem better and I was trying to read the source for Howdy to see how to do it, so far no luck.

I find it funny that this is the first video where I’m consistently getting the “This helps us protect our community” and “Log in to confirm that you are not a bot” errors while using an alternative Frontend.
I’m sure it’s just a random coincidence, but it is still funny to me.
This was an interesting question, so I took a quick dive in the docs, it seems it has an S3 integration to help with it, and some comments on the various supported services
More info here: https://owncast.online/docs/storage/
Still, depending on the chosen provider and the amount of viewers, it could be quite costly
It’s an error with a dependency written in Rust, the workaround is to use an older toolchain (1.72), it is fixed in the newer code of tokenizers, but probably it is not updated in AUTOMATIC1111 yet: you should check their bug tracker
To have more info you can read this issue: Link
Considering you are not using the Flatpak anymore it is, indeed, strange. The only reasons I can think of are: your network manager is using the wrong network interface to route your traffic ( if you go on an ip checking site like for example ipinfo do you see yours or the VPN’s IP?) or that you have WebRTC enabled and the broadcaster is getting your real ip through that.
For the first case it can get pretty complicated, but it is probably an error during the installation of the VPN app or you set up multiple network managers and it gets confused on which one to configure. You should also enable the Advanced Kill Switch in the configuration.
For the second case you could try adding something like the Disable WebRTC add-on for firefox and check if it works. Remember to enable it for Private Windows too.
The last thing I can think of is that you allowed the broadcaster to get your real geolocation (in firefox it should be a small icon on the left of the address bar), or you are leaking some kind of information somewhere: there are a bunch of site that check for ip leak, but I don’t know if that goes too deep for you.
If you want to check anyway the first two results from DDG are browserleaks and ipleak. Mullvad offered one too but it is currently down.
EDIT: If you enable the Advanced Kill Switch, and the app is working correctly, internet will not work while you are not connected to a VPN server or until you disable the switch again, so pay attention to that.

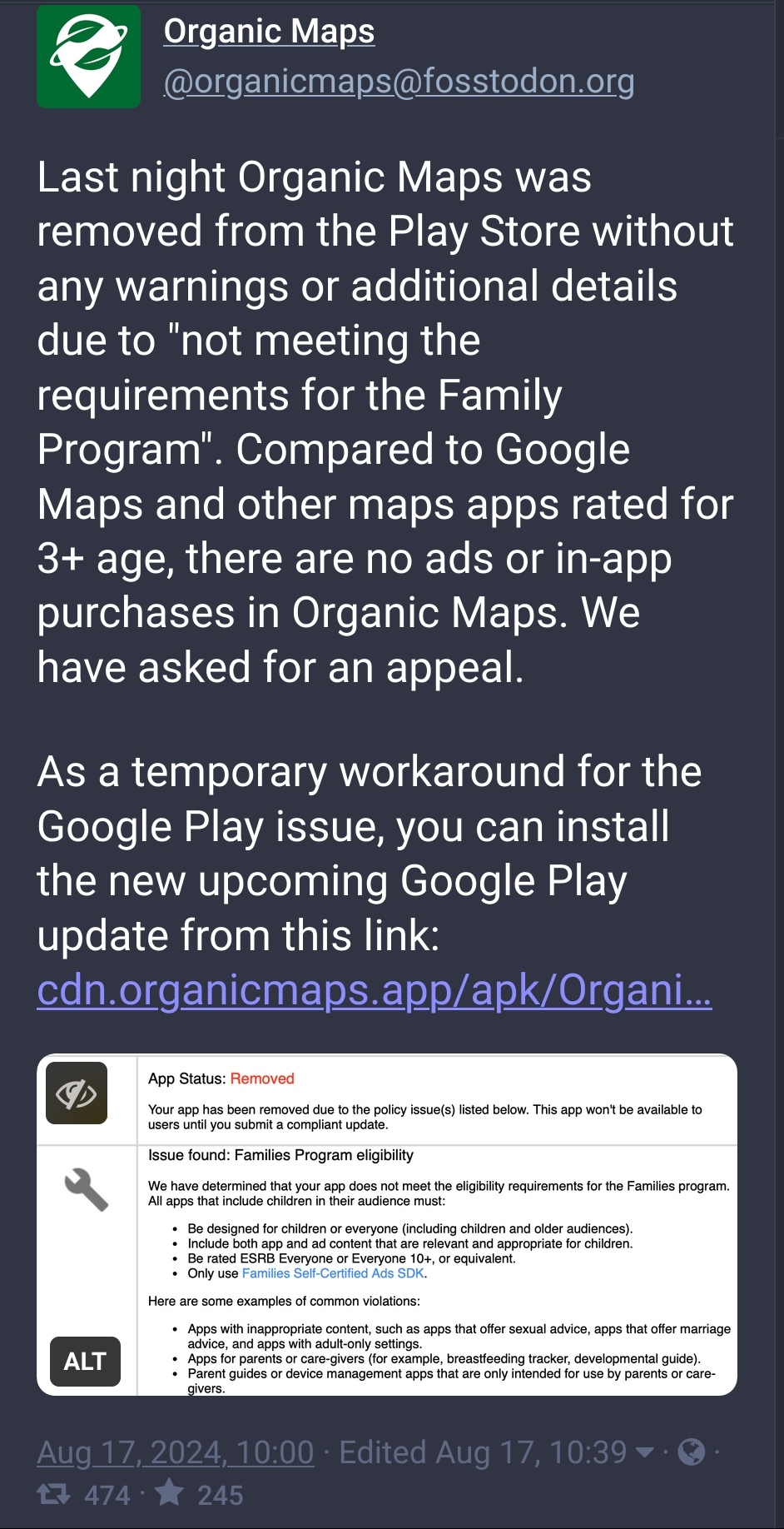{kind=link}
I don’t have direct experience with RooCode and Cline, but I would be mighty surprised if they work with lesser models of even the old Qwen2-Coder 32B - and even that was mostly misses. I never tried the Qwen3 coder but I assume it is not drastically different.
Those small models are at most useful for some kind of smarter autocomplete, not to run a full tools framework.
BTW you could check out Aider too for a different approach, and they have a lot of benchmarks that can help you get an idea about what’s needed.