

They are referencing this paper: LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset from September 30.
The paper itself provides some insight on how people use LLMs and the distribution of the different use-cases.
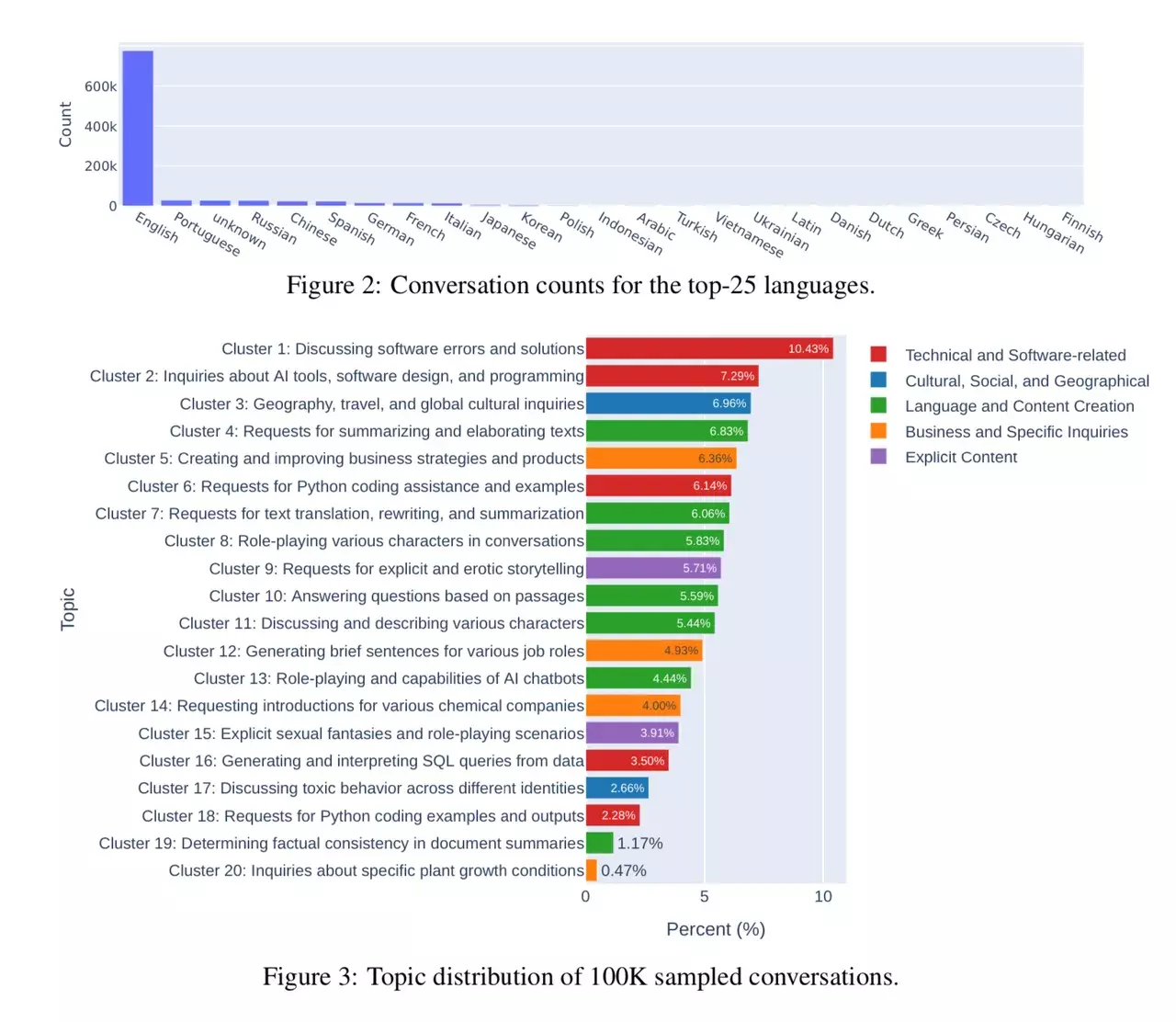
The researchers had a look at conversations with 25 LLMs. Data is collected from 210K unique IP addresses in the wild on their Vicuna demo and Chatbot Arena website.
That is also my observation. Even for (simple) tasks like summarization, I’ve seen LLMs insert to much inaccurate information to be useful for my own life. The tasks I see are somewhat narrow and require a human in the loop. Despite some people claiming we’re close to AGI.